制作一个gitbook插件: 页面title改为层级显示
背景
默认gitbook生成的title是 本页面的标题 · 书名
然而很奇怪
例如一级目录是JS 其下一个page的标题为入门 书名叫404k的前后端日志
这样生成html的标题就为 入门 · 404k的前后端日志
而这样对SEO可能并不友好
我觉得 入门 · JS · 404K的前后端日志
这样可能会好点
然后就撸起袖子
学习gitbook插件
首先建议可以先看看
https://toolchain.gitbook.com/plugins/create.html 了解其gitbook提供的钩子和API
主要的结构为入口js 例如index.js
module.exports = {
// Map of hooks
hooks: {},
// Map of new blocks
blocks: {},
// Map of new filters
filters: {}
};
一般主要用hooks,可以监听page生成前和生成时
block和filters主要是自定义数据模板的
修改最终的文件
最后的思路是
- 利用page:before(page事件也行)中的page对象收集level、title和basename
- 获取最终文件生成路径,第一步收集的basename,则用于寻找最终生成的.html文件
- 获取.html文件中的title,根据title匹配上level
- 根据当前level,找出父目录的title
- 用node进行文件修改title
怎么过程通过Promise写,比较清晰,具体代码在文章最下面
收集 level,title和basename
最终收集的数据类似
{
"level": "1.7.1",
"title": "只有偏执狂才能生存",
"basename": "zhi_you_pian_zhi_kuang_cai_neng_sheng_cun"
},
{
"level": "1.8",
"title": "设计",
"basename": "she_ji"
},
{
"level": "1.8.1",
"title": "至美用户人本设计剖析",
"basename": "zhi_mei_yong_hu_ren_ben_she_ji_pou_xi"
}
```
实现的代码比较简单
```javascript
"page:before": function (page) {
title_array.push({
level: page.level,
title: page.title,
basename: page.path.substring(0, page.path.lastIndexOf('.') )
});
return page;
},
获取最终生成的.html文件
这里注意的是README.md最终生成的是index.html而非README.html,这个需要特殊处理
if (element.basename !== 'README') {
element.file_path = path.join(output,element.basename + ".html")
}else {
element.file_path = path.join(output,'index' + ".html")
}
return element
读取内容
return new Promise( resolve => {
fs.readFile( element.file_path, (err, data) => {
if (err) throw err
element.content = new String(data)
resolve( element )
})
})
设置新title
let title = (( element.content ).match(new RegExp("<title>(.+)· " + book_title ) ) )[1].slice(0, -1), //去掉最后匹配多出来的空格
title_object = _.find(title_array, function(element){
if (element.title === title) return true
}),
level = title_object.level
while(true){
level = level.substring(0, level.lastIndexOf('.'))
title_object = _.find(title_array, function(element){
if (element.level === level) return true
})
if ( !title_object ) break;
title += ' ' + title_object.title
}
element.new_title = title
return element
更换title
element.content = element.content.replace(/<title>(.+)<\/title>/,function(match, p1){
return '<title>' + element.new_title + ' · ' + book_title + '</title>'
})
return element
新title写入文件
fs.writeFile(element.file_path, element.content, function(err){
if (err) throw err
} )
尝试过的失败
直接修改hooks中的page:before
page:before函数中有page.title属性,但是修改了并没什么用,title依旧
一般page.content修改就很好使
hooks中的navigation修改title
hooks: {
"init": function(){
for(key in this.navigation) {
this.navigation[ key ].title = 12345;
}
console.log(circular_json.stringify(this, null, 4))
},
然而这并没有修改到title
遇到的技术点
箭头函数和arguments变量
平常在调试时,喜欢用arguments来获取所有参数
例如
var a = function(){
console.log(arguments)
}
a(1) //{ '0': 1}
但是如果写成
var a = () => {
console.log(arguments)
}
a(1)
输出的则是{ '0': {} }
箭头函数是不支持arguments,的如果需要获取所有参数,需要...变量
var a = (...args) => {
console.log(args) //[1]
}
找资料中的额外发现
//小提示:当使用箭头函数创建普通对象时,你总是需要将对象包裹在小括号里。
// 为与你玩耍的每一个小狗创建一个新的空对象
var chewToys = puppies.map(puppy => {}); // 这样写会函数会返回undefined
var chewToys = puppies.map(puppy => ({})); //
参考资料http://www.infoq.com/cn/articles/es6-in-depth-arrow-functions
正则中添加变量
例如需要匹配.html中的title
<title>TCP-IP详解 卷一: 协议 · 404k的阅读笔记</title>
一开始匹配title用的正则是/<title>(\S+)/
一般没有空格的都是ok的,但是上面这周自己title有空格的话就只匹配到TCP-IP详解,这样的title匹配不到level的
所以当时的想法书名也匹配进来,不过404k的阅读笔记是个变量,每本书都不一样,怎么往正则加这个呢
定义正则的方法有字变量和构造函数,而字变量尝试了几波误解...只好用字变量
所以最后正则变为
new RegExp("<title>(.+)· " + book_title ),//book_title为404k的阅读笔记
获取到title还需要.slice(0, -1)掉后面的空格.
参考链接http://www.cnblogs.com/season-huang/p/3544873.html
slice, substr, substring的区别
主要区别有
- 只有slice支持负数
- substring会对参数1和参数2进行大小比较,小的替换为参数1,大的替换成参数2
- substr的参数2表示截取的长度,而其他两个都代表截取到字符串的哪一位
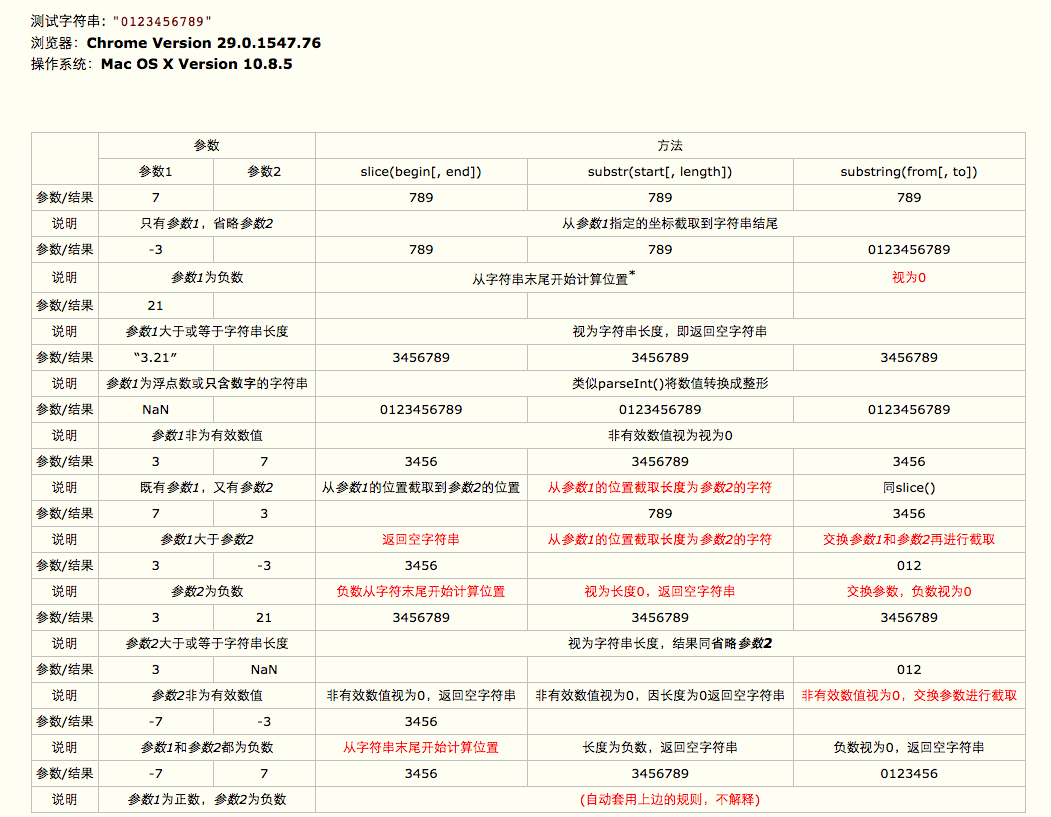
参考链接http://www.cnblogs.com/ider/p/js-slice-vs-substr-vs-substring-table.html
过程promise
之前用以前普通的写法缺点有
- 有读写文件回调,嵌套感觉不爽
- 很多错都没catch到,如果再全部加一层 try catch 感觉更乱
无promise代码
_.each(title_array, function(element){
//fs.readFileSync()
let file_path
if (element.basename !== 'README') {
file_path = path.join(output,element.basename + ".html")
}else {
file_path = path.join(output,'index' + ".html")
}
fs.readFile(file_path, function(err, data){
if (err) {
console.log(err)
return
}
let content = new String(data),
result = content.match(/<title>(\S+)/),
default_title = result && result[1],
title_object = _.find(title_array, function(element){
if (element.title === default_title) return true
})
level = title_object && title_object.level,
new_title = default_title
while(true){
level = level && level.substring(0, level.lastIndexOf('.'))
title_object = _.find(title_array, function(element){
if (element.level === level) return true
})
if ( !title_object ) break;
new_title += ' ' + title_object.title
}
content = content.replace(/<title>(\S+)<\/title>/,function(match, p1){
return '<title>' + new_title + ' · ' + book_title + '</title>'
})
fs.writeFile(file_path, content, function(err){
if (err) throw err
} )
console.log(file_path)
console.log(result&& result[1])
console.log(new_title)
}.bind(null, file_path))
})
Promise后代码
_.each(title_array, element => {
Promise.resolve()
.then( () => { //查找html
if (element.basename !== 'README') {
element.file_path = path.join(output,element.basename + ".html")
}else {
element.file_path = path.join(output,'index' + ".html")
}
return element
})
.then( element => { //读取内容
return new Promise( resolve => {
fs.readFile( element.file_path, (err, data) => {
if (err) throw err
element.content = new String(data)
resolve( element )
})
})
})
.then( element => { //获取新title
let title = (( element.content ).match(new RegExp("<title>(.+)· " + book_title ) ) )[1].slice(0, -1),
//let title = (( element.content ).match(/<title>(\S+)/) )[1],
title_object = _.find(title_array, function(element){
if (element.title === title) return true
}),
level = title_object.level
while(true){
level = level.substring(0, level.lastIndexOf('.'))
title_object = _.find(title_array, function(element){
if (element.level === level) return true
})
if ( !title_object ) break;
title += ' ' + title_object.title
}
element.new_title = title
return element
})
.then ( element => { //设置新title
element.content = element.content.replace(/<title>(.+)<\/title>/,function(match, p1){
return '<title>' + element.new_title + ' · ' + book_title + '</title>'
})
return element
})
.then( element => { //新title都到文件中
fs.writeFile(element.file_path, element.content, function(err){
if (err) throw err
} )
} )
.catch(err => {
console.log(err)
})
})